arksys
معجزه قدرت ، هوش و عشق را به امانت داری --- خوب و بد سرنوشت را تو خودت مختاریarksys
معجزه قدرت ، هوش و عشق را به امانت داری --- خوب و بد سرنوشت را تو خودت مختاریبررسی مفهوم یادگیری ماشین
ماشینهای مصنوعی میتوانند یک سری وظایف خاص را بدون استفاده از دستورات مشخص و تنها با استفاده از الگوریتمها و مدلهای آماری انجام دهند. یادگیری ماشین (machine learning) به روشهای یادگیری وظایف ماشین با استفاده از این الگوریتمها و مدلها گفته میشود. به عبارتی، یادگیری ماشین زیرشاخهای از هوش مصنوعی است و سیستمهای مصنوعی هوشمند به منظور یادگیری مسائل، از روشهای یادگیری ماشین استفاده میکنند.
- دریافت دادههای ورودی
- آمادهسازی دادهها برای مدل
- انتخاب مدل یادگیری
- آموزش مدل
- ارزیابی مدل
- پیشبینی خروجی برای داده جدید
انواع روش های یادگیری ماشین کدامند ؟
سیستمهای مصنوعی هوشمند با دریافت دادههای ورودی به دنبال حل مسئلهای خاص هستند. دادههای ورودی این سیستمها میتوانند انواع مختلفی داشته باشند که با توجه به نوع داده ورودی، رویکرد یادگیری مسئله نیز تغییر خواهد کرد. روشهای یادگیری ماشین را میتوان به چهار دسته کلی تقسیم کرد:
- یادگیری نظارت شده(Supervised Learning)
- یادگیری بدون نظارت(Unsupervised Learning)
- یادگیری نیمه نظارت شده(Semi-supervised Learning)
- یادگیری تقویتی(Reinforcement Learning)
روشهای یادگیری ماشین :
یادگیری نظارت شده
یادگیری نظارت شده رویکردی برای یادگیری سیستمهای مصنوعی هوشمند است که الگوریتمهای مبتنی بر این رویکرد، با استفاده از دادههای آموزشی برچسبدار (Labeled Training Data) مسئله خاصی را یاد میگیرند. برچسبهای داده، خروجیهای مدل را مشخص میکنند. در این روش، آموزش مدل تا زمانی ادامه خواهد داشت که بتواند الگوهای دادههای آموزشی و روابط بین دادههای آموزشی و برچسبهای خروجی را تشخیص دهد.
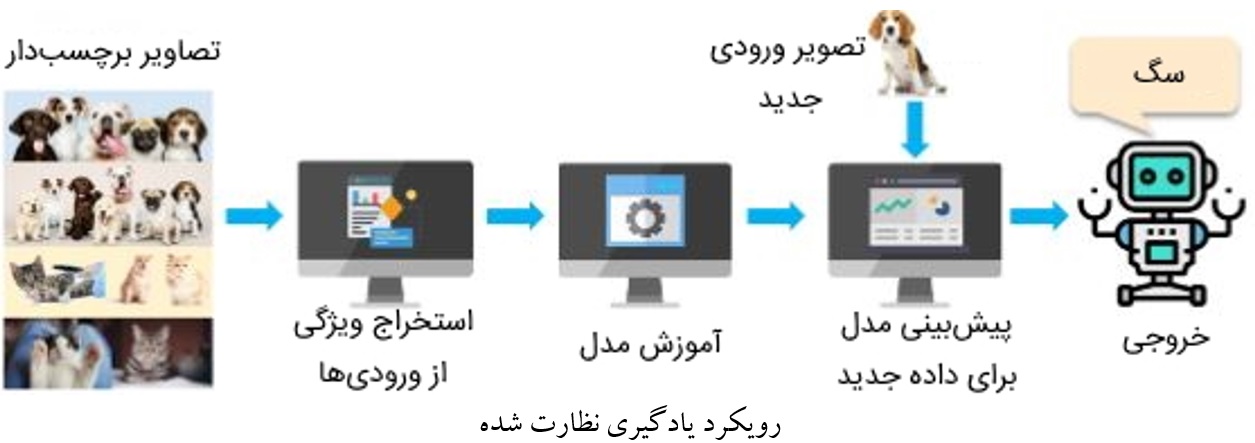
میزان دقت مدل به دادههای آموزشی برچسبدار و الگوریتم انتخابی بستگی دارد. دادههای آموزشی باید تمیز باشند و تعادل بین تعداد دادهها با برچسبهای مختلف حفظ شود. همچنین، دادههای آموزشی تکراری بر عملکرد مدل تاثیرگذار هستند. بهعلاوه، تنوع در دادههای آموزشی باعث میشود که مدل بتواند عملکرد بهتری برای دادههای تست (Test Data) یا دادههای جدید و مشاهده نشده از قبل داشته باشد. بدین ترتیب، افراد برنامه نویس یا اشخاص فعال در حوزه علوم داده باید زمان و دقت زیادی را صرف آمادهسازی دادههای آموزشی کنند.
از رویکرد یادگیری نظارت شده میتوان در مسائل دستهبندی (Classification) و رگرسیون(Regression) استفاده کرد که برای حل هر یک از این مسائل، الگوریتمهای مختلفی وجود دارد. در ادامه، به توضیح این دو نوع مسئله پرداخته میشود.
الگوریتم های دسته بندی
از الگوریتمهای دستهبندی یادگیری ماشین به منظور مشخص کردن دسته یا کلاس دادهها استفاده میشود. برچسب دادههای آموزشی، دسته یا کلاس دادهها را مشخص میکنند و الگوریتمهای دستهبندی، با تشخیص الگوهای دادهها و برچسب آنها به یادگیری مسئله میپردازند تا در زمان تست، با دریافت داده جدید، نوع دسته یا همان برچسب داده را تشخیص دهند.
از الگوریتمهای دستهبندی میتوان برای مسائلی با دستهبندی دودویی(Binary Classification) نظیر تشخیص اسپم یا غیراسپم بودن ایمیل و تعیین مثبت یا منفی بودن نظر مشتری درباره یک محصول استفاده کرد. همچنین، میتوان این نوع الگوریتمها را برای مسائلی به کار برد که برای دادهها، چندین کلاس تعریف شده است. موضوعاتی نظیر تشخیص حروف نوشتههای متن، دستهبندی داروها بر اساس ویژگیهای مشترک و تشخیص نویسنده متن از این دست مسائل هستند.
مدل های رگرسیون
در مسائلی که با مدلهای رگرسیون قابل حل هستند، به دنبال این هستیم که رابطه عددی بین دادههای ورودی و مقدار خروجی را مشخص کنیم. به عبارتی، در این مسائل، برخلاف موضوعات دستهبندی، کلاسی برای دادهها تعریف نمیشود، بلکه هر مقدار ورودی میتواند یک مقدار خروجی منحصربفرد داشته باشد. موضوعاتی نظیر پیشبینی قیمت مسکن با توجه به ویژگیهای آن را میتوان به عنوان مسئلهای در نظر گرفت با مدلهای رگرسیون پیادهسازی میشوند.
یادگیری بدون نظارت
تفاوت رویکرد یادگیری بدون نظارت با رویکرد یادگیری نظارت شده، شیوه حل مسئله و آمادهسازی دادههای آموزشی است. به عبارتی، الگوریتمهای یادگیری بدون نظارت نیازی به دادههای برچسبدار ندارند. این الگوریتمها، دادههای آموزشی را بر اساس ویژگیهای مشابه دادهها، آنها را در گروههای مختلف خوشهبندی(Clustering) میکنند.
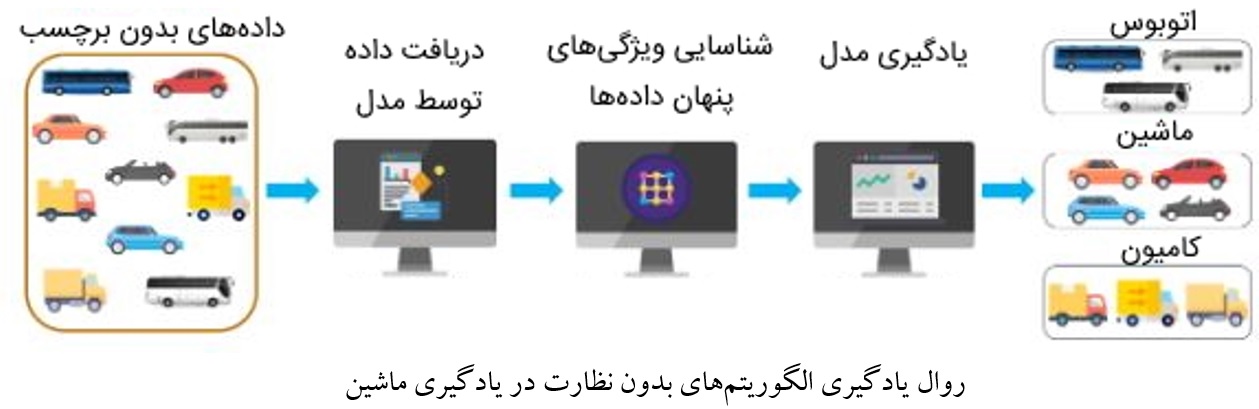
یکی از مزیتهای اصلی رویکرد یادگیری بدون نظارت نسبت به رویکرد یادگیری نظارت شده این است که در روشهای خوشهبندی، نیازی به دخالت انسان نیست و دادهها صرفاً با توجه به شباهتشان در گروههای مجزا قرار میگیرند. بدین ترتیب، نظر شخصی افراد در تشخیص دسته دادهها دخیل نمیشوند. همچنین، از آنجا که رویکرد یادگیری بدون نظارت به دادههای برچسبدار نیاز ندارد، در هزینههای مالی و زمانی صرفهجویی خواهد شد.
یادگیری نیمه نظارت شده
زمانی که برای حل مسئلهای قصد داریم از رویکرد یادگیری نظارت شده استفاده کنیم اما تعداد دادههای برچسبدار مورد نیاز کم هستند، میتوان از رویکرد یادگیری نیمه نظارت شده استفاده کرد. الگوریتمهای یادگیری ماشین که مبتنی بر این رویکرد هستند، میتوانند برای آموزش از هر دو دادههای برچسبدار و بدون برچسب استفاده کنند. روال یادگیری این نوع از الگوریتمها به این صورت است که در ابتدا همانند رویکرد یادگیری بدون نظارت، روابط بین دادههای آموزشی مشخص میشوند و سپس مدل از دادههای برچسبدار استفاده میکند تا برچسب کلیه دادهها را مشخص کند.
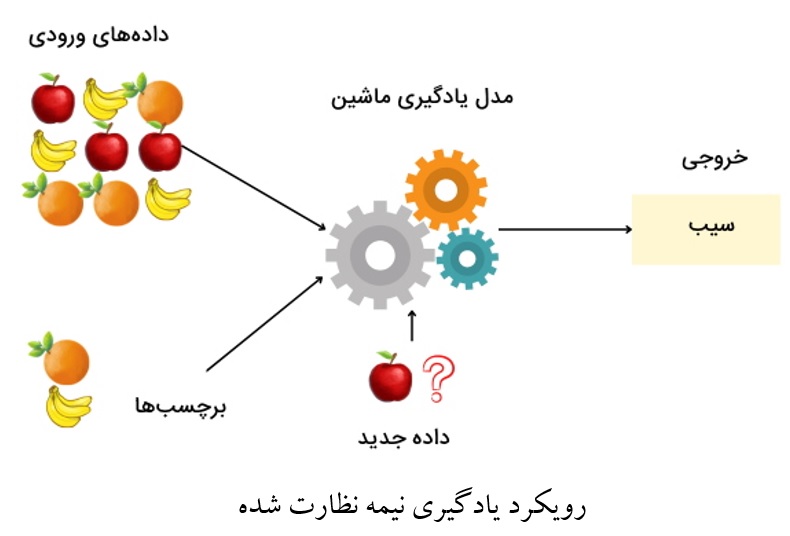
الگوریتمهایی که مبتنی بر رویکرد نیمه نظارت شده هستند، برای مسائل دنیای واقعی کاربرد مناسبتری دارند، زیرا دادههای برچسبدار در مسائل واقعی در مقایسه با دادههای بدون برچسب کمتر هستند. از آنجه که این رویکرد برای بهبود نتایج و رسیدن به دقت بالاتر از دادههای بدون برچسب نیز استفاده میکند، در بسیاری از مسائل، دقت حاصل شده بهتر از الگوریتمهای نظارت شده با دادههای محدودتر هستند. یکی از موضوعاتی که میتوان آن را با استفاده از رویکرد یادگیری نیمه نظارت شده پیادهسازی کرد، مسئله تشخیص چهره است. در این مسئله تعداد زیادی تصویر از اشخاص متفاوت وجود دارد که بر اساس شباهت تصاویر، الگوریتمهای نیمه نظارت شده، آنها را در خوشههای مجزا گروهبندی میکنند و سپس با استفاده از برچسبهای دادههای آموزشی، برای هر خوشه، برچسب مناسبی در نظر گرفته میشود.
یادگیری تقویتی
در مقایسه با سایر رویکردهای یادگیری ماشین، الگوریتمهای مبتنی بر یادگیری تقویتی، رویکرد متفاوتی برای یادگیری دارند. مدلهای یادگیری تقویتی بر مبنای بازخورد از محیط، مسائل را یاد میگیرند. به عبارتی، در این رویکرد، عاملی هوشمند(Agent) وجود دارد که در ازای اقداماتی که در یک محیط انجام میدهد، پاداش یا تنبیه دریافت میکند. چنانچه عامل، عملی را در راستای رسیدن به هدف انجام دهد، بازخورد مثبتی دریافت خواهد کرد و در صورتی که اقدامی نادرست را انجام دهد، بازخوردی منفی دریافت خواهد کرد. هدف نهایی عامل، رسیدن به بیشترین تعداد بازخوردهای مثبت است.
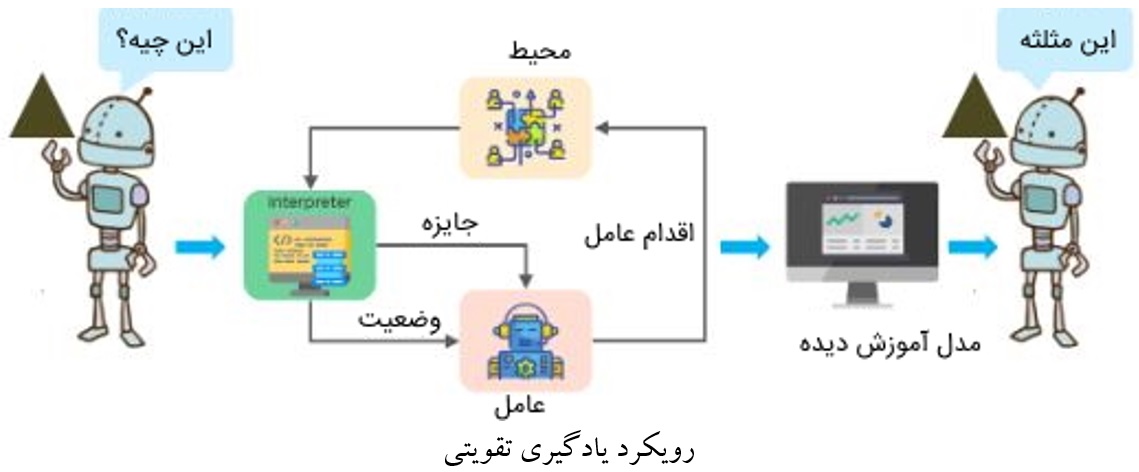
در این رویکرد از یادگیری، نیازی به دادههای آموزشی برچسبدار نیست و عامل صرفاً بر اساس بازخوردهایی که از محیط دریافت میکند، اقدامات درست و نادرست را یاد میگیرد. بدین ترتیب، میتوان گفت که یادگیری عامل مبتنی بر تجربههای حاصل شده است. از آنجا که مدلهای یادگیری ماشین مبتنی بر یادگیری تقویتی نیازی به تهیه دادههای آموزشی ندارند، میتوانند به عنوان روشهای مناسبی برای حل مسائل واقعی محسوب شوند. به عنوان مثال، از این مدلها میتوان برای آموزش بازیهای کامپیوتری و کنترل خط تولید کارخانهها استفاده کرد.
ویژگی های یادگیری ماشین برای درک تفاوت هوش مصنوعی و یادگیری ماشین
به منظور درک بهتر تفاوت هوش مصنوعی و یادگیری ماشین بهتر است به ویژگیهای یادگیری ماشین نیز پرداخته شود. یادگیری ماشین به دلیل داشتن ویژگیهای مهم و کاربردی، در سالهای اخیر مورد توجه بسیاری از سازمانها قرار گرفته است و شرکتهای بسیاری، از مدلهای آن به منظور پیشبرد اهداف خود استفاده میکنند. در ادامه، به برخی از مهمترین ویژگیهای یادگیری ماشین اشاره شده است:
- قابلیت مصورسازی دادهها به صورت خودکار
- خودکارسازی وظایف با بالاترین کارایی
- تغییر در روشهای تعامل با مشتری
- تجزیه و تحلیل دقیق دادهها
- تقویت هوش تجاری(Business Intelligence)
قابلیت مصور سازی خودکار داده با استفاده از یادگیری ماشین
روزانه حجم عظیمی از داده در شرکتها و سازمانها تولید میشوند. با مصورسازی دادهها میتوان به تجزیه و تحلیل آنها پرداخت و الگوهای خاصی را بر اساس روابط بین دادهها استخراج کرد. چنین اطلاعاتی، در تصمیمگیری و گام برداشتن به سوی اهداف سازمان کمک بهسزایی میکنند. ابزارهای مبتنی بر یادگیری ماشین قادر هستند از دادههای ساختاریافته (Structured) و غیرساختاریافته(Unstructured) چنین اطلاعاتی را استخراج کنند و این اطلاعات را در قالب پلتفرمهای بصریسازی داده، در اختیار کارکنان و مدیران سازمان قرار دهند.
قابلیت خودکارسازی وظایف با بالاترین کارایی با استفاده از یادگیری ماشین
یکی از مهمترین ویژگیهای مدلهای یادگیری ماشین، انجام وظایف تکراری با بالاترین دقت و در سریعترین زمان ممکن است. برخی از سازمانها برای انجام یک سری وظایف ثابت و تکراری از مدلهای مبتنی بر یادگیری ماشین استفاده میکنند که در پی آن، هزینه مالی و زمانی آنها بهطور چشمگیری کاهش پیدا میکند.
قابلیت تغییر در روشهای تعامل با مشتری با ماشین لرنینگ
یکی از مهمترین روشهای تبلیغات محصولات و خدمات سازمانها و جذب مشتریان و حفظ آنها بهصورت طولانی مدت، برقراری مکالمات موثر است. بدین منظور میتوان از مدلهای یادگیری ماشین استفاده کرد تا مکالمات و ارتباطات موثری را با مشتریان برقرار کند. ابزارهایی که برای تحقق چنین هدفی طراحی شدهاند، جملات، کلمات، عبارات و نظرات مشتریان را با استفاده از الگوریتمهای یادگیری ماشین تجزیه و تحلیل میکنند و با توجه به نیازمندیها و علایق مشتریان، محصول و خدمات مورد نیاز را به آنها پیشنهاد میدهند. سایت Pinterest میتواند نمونه خوبی برای کاربرد یادگیری ماشین باشد که بر اساس علاقهمندیهای کاربر و موضوعاتی که بیشترین جستجو را درباره آن داشته است، به او پیشنهاداتی ارائه میدهد.
قابلیت تجزیه و تحلیل داده ها با استفاده از یادگیری ماشین
یکی از نیازمندیهای سازمانها، بررسی و تجزیه و تحلیل دادههای سازمانی است که با استفاده از اطلاعات و گزارشات استخراج شده از نتایج بررسی آنها، بتوان تصمیمات مهم و اساسی در راستای پیشبرد اهداف سازمان گرفت و به سوددهی بیشتری رسید. یکی از موثرترین روشهای تجزیه و تحلیل دادهها با دقت بالا، استفاده از ابزارهای مبتنی بر یادگیری ماشین است. این مدلها، در کوتاهترین زمان، حجم زیادی از دادهها را تحلیل میکنند و نتایج را در فرمتهای مختلف ارائه میدهند.
تقویت فرآیند هوش تجاری با یادگیری ماشین
یادگیری ماشین به عنوان یکی از موثرترین تکنولوژیها برای بهبود عملیات تجاری محسوب میشود. به عبارتی، مدلهای یادگیری ماشینی که در هوش تجاری استفاده میشوند، به کسب و کارها کمک میکنند تا اطلاعات ارزشمندی را از دادههای گذشته سازمان استخراج کنند تا مدیران با بررسی آنها بتوانند از دلایل پیشرفت یا شکست سازمان آگاه شوند.
منبع: فرادرس